
哈希函数构造方法
Hash Function
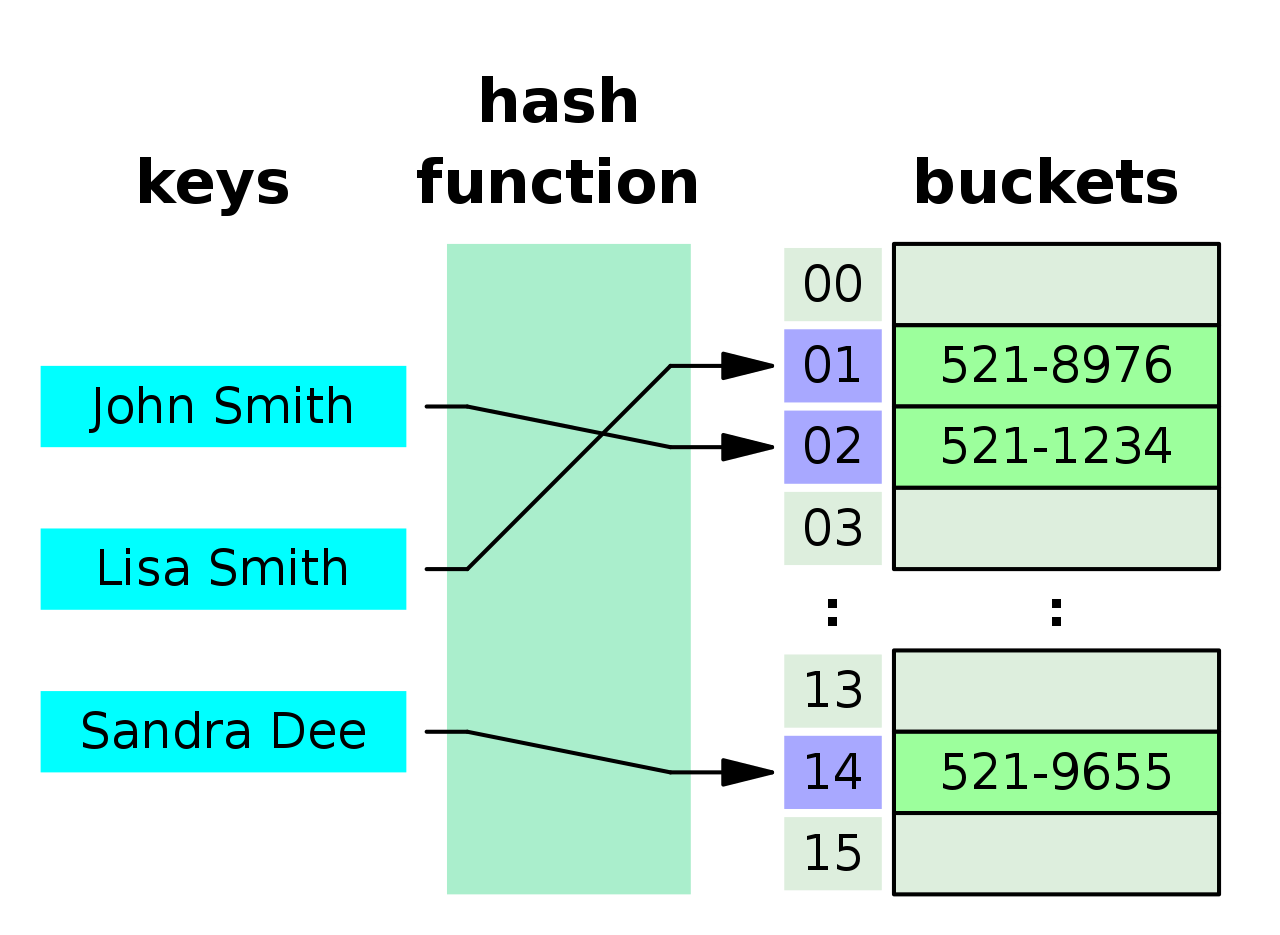
哈希函数是把 key 转换成整数索引的工具,核心目标是快速定位 + 尽量少冲突,是哈希表性能的关键。
1.直接定址法
直接使用关键字本身作为哈希函数,公式h(key) = key。
优点是没有冲突。缺点是比较浪费空间。
2.除留余数法
将key对p取模(p一般取小于等于表长的最大质数)。取质数可以使得模运算的结果有更好的分布特性,非质数p可能与key存在公因数,导致哈希值集中分布。
比如
10 20 30 40 50如果p取10,模运算结果都是0,如果p取7,那么就可以更好的分布。
使用除留余数法优点是节省空间,也是最常用的哈希函数。缺点是会产生哈希冲突。
解决哈希冲突
开放定址法
- 线性探测法
发生冲突的时候,继续探测下一个位置,直到找到空闲位置。
注意的是,使用线性探测法,删除元素的时候不应该直接删除,而是应该打上一个删除标记

- 平方探测法

拉链法
为每个哈希地址建立链表,遇到哈希冲突直接将元素放到链表中。JDK1.7采用头插法,JDK1.8采用尾插法。
头插法时间复杂度是O(1),但是在并发环境下可能会造成死循环。
哈希表的大小
哈希表的大小一般都设置成2的幂次方,设置成这样是有理由的。
我们计算哈希索引是通过x % size得到的,这里的x是经过一定的处理运算的。
当size = 2 ^ n的时候,x % size = x & (size - 1),位运算是一个非常快的操作,相比使用模运算可以提高性能。
x % size等价于取x的低n位,因为size = 2 ^ n,模运算的结果范围是[0, 2 ^ n - 1]
x & (size - 1),由于size - 1的低n位全是1,所以也是等价于取x的低n位,这两个操作的结果实际是相等的。
用户在初始化哈希表的时候,设定的大小可能并不是2的幂次方,那么我们就需要一种算法,可以将任意大小的数转换成离它最近的,大于它的,并且是2 ^ n的数。
HashMap源码里是这样实现的

这里先不用考虑为什么n = cap - 1然后在最后返回结果的时候+1,后面自然会明白。先往下看,
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;我们要把任意大小的数变成离他最近的大于它的并且是2^n的数,相当于就是把最高位的1后面所有位都变成1,我们通过上面操作就可以实现。
这里的">>>"是无符号右移,为什么用它也先忽略,反正是起到右移效果,不过是无符号。
我们第一次右移,达成了一个效果,那就是最高位的1的左边的位也变成了1,所以第二次右移直接移动两位,这样从最高位往左开始数,就确保连续4个位都变成了1,以此类推,31位都变成了1。
然后讲讲为什么用无符号右移,因为如果这个n是负数,那么向右移动会带上符号位1,打乱我们的计划。
为什么要int n = cap - 1?
假设cap = 8
如果不做n = cap - 1
cap = 8 = 0000 1000 (二进制)
染色后 = 0000 1111 (15)
结果返回染色值 + 1 = 16这时候结果16并不是离它最近的,最近的是8
如果n = cap - 1
n = 7 = 0000 0111
染色后 = 0000 0111
返回 n + 1 = 8说白了就是当cap本身是2的幂次方的时候,确保最后计算结果仍然是cap
HashMap多线程环境下冲突的问题
- 数据覆盖问题
多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在JDK 1.7和 JDK 1.8 中都存在。
- JDK1.7头插法导致死循环问题
JDK1.7的HashMap使用头插法插入元素,在扩容的时候可能导致环形链表的出现。具体可以参考下面视频。JDK1.8采用尾插法解决了这个问题。
【Java面试】带你深入理解 为什么HashMap会产生死循环?_哔哩哔哩_bilibili
扩容
JDK1.7 扩容
- 新数组:扩容后创建一个新的更大的数组(容量翻倍)。
遍历老数组:遍历老数组的每一个桶(链表),每个桶里的元素都会重新计算
hash。- 重新计算 hash:需要重新算一次 hash 值。
- 取模计算位置:根据新的
newCapacity,使用(newHash & (newCapacity - 1))来确定新位置。
- 链表重新分配:把原数组中所有的元素,按照新的数组大小,重新分配到新数组的相应位置。链表顺序反转,采用头插法。
总结:JDK1.7 需要重新计算哈希值,且扩容后链表的顺序可能反转。
JDK1.8 扩容
- 新数组:扩容后创建一个新的更大的数组(容量翻倍)。
遍历老数组:遍历老数组的每一个桶(链表或红黑树)。
- 不重新计算 hash:直接使用原来的
hash,不需要重新计算。 按高位判断:使用
hash & oldCapacity来判断元素应该留在原桶,还是移动到新的桶(index + oldCapacity)。hash & oldCapacity == 0:表示该元素应留在原位置(不变)。hash & oldCapacity == 1:表示该元素应移动到新位置(index + oldCapacity)。
- 不重新计算 hash:直接使用原来的
链表/红黑树拆分:
链表:将链表里的每个节点按
hash & oldCapacity分成两条链表:- 结果为
0→ 留在原桶; - 结果为
1→ 放到新桶(index + oldCapacity)。 - 链表顺序保持不变,直接挂到新数组上。
- 结果为
红黑树:也按同样规则拆成两个部分,分别放到原桶和新桶;
- 如果拆出的子树节点数 ≤ 6,退化为链表。
总结:JDK1.8 优化了扩容过程,不需要重新计算 hash,扩容后链表顺序不变,红黑树可以拆分。
链表退化为红黑树
在 JDK 1.8 中,HashMap 对链表进行了优化,当链表的长度过长时,会考虑把链表转换为 红黑树,这样可以大大提高查询效率,避免链表查找的时间复杂度变得过高。
链表退化为红黑树的条件如下:
链表长度 ≥ 8:当某个桶中的链表长度达到 8 时,JDK 1.8 会考虑将链表转换为红黑树。
数组大小 ≥ 64:为了防止在数组较小的情况下引起不必要的红黑树构建,只有在数组大小达到 64 时,才会触发链表转换为红黑树。这是为了保证红黑树的性能优势不会因为数组容量小而变得不明显。




